Great Wall Motor's electric car brand, GWM Ora, has been turning heads in Asia since 2018 and has been selling its particular kind of style in Europe since 2022. A subsidiary of the global automotive behemoth Great Wall Motor (GWM) is based in Baoding, China. GWM has been looking to offer a premium, technology-rich driving experience, combined with unique design and human-centric intelligent technologies.
However, despite early rumours that GWM's Ora models would start close to £25,000, the model we reviewed back in December 2022 was actually closer to £32,000. Some say that the Ora's pricing puts it too close to the ID.3, MG4 and other cars with more range and higher specifications. The BYD Dolphin is around £2,000 cheaper, but with better performance and increased range.
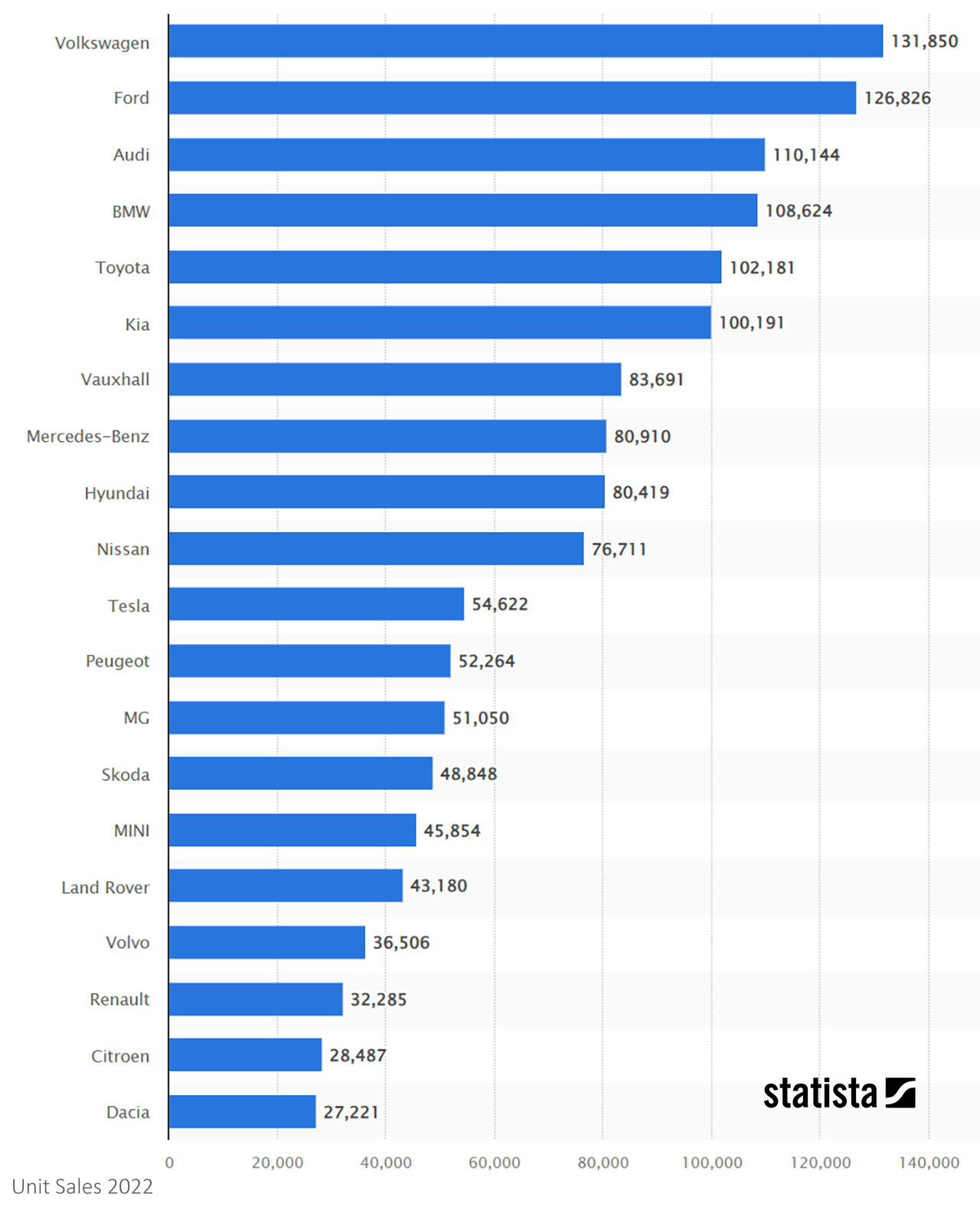
The five largest car makers in the UK, sold over 570,000 cars between them in 2022. Tesla only sells EVs and it managed almost 55,000 sales. When GWM announced that they have finally passed the 1,000 units sold mark (but it took them more than a year), you can see the size/nature of the challenge. Even smaller brands like Dacia, still managed to sell 27,000 cars in 2022.
In the face of all these obstacles, GWM is trying a new approach.
As part of its ongoing strategy, GWM Ora has introduced a new naming convention for all its current and future models. The brand's first model, formerly known as the ORA Funky Cat, has been rebranded as ORA 03 and will be available in two trim levels: PURE+ and PRO+.
At the same time, the company is bringing 0% finance packages to the UK market in an attempt to boost sales. The Ora 03 Pure+ variant has 0% APR finance offer starting at £228 a month, with an initial payment of £9,125 and a final payment of £17,395. This model includes wireless phone charging, facial recognition, electric front seats, app integration and the ‘Hello ORA' intelligent voice assistant. It has a 48kWh battery, range of 193 miles (WLTP), a top speed of 99 mph and a 0-60 in under 8.3 seconds. It pulls DC current at 67kW and AC at 6.6kW – so charging times are not that fast.

The Ora 03 PRO+ variant starts at £298 a month, steps up with a larger 63kWh battery for 261 miles of WLTP range. This model comes with front seats that will heat up, cool down and massage occupants. There's also a heated steering wheel, panoramic sunroof, rear privacy glass, and automatic parking assistance. The baseline price of £34,995 can be financed with a deposit of £7,600 over 3 years with a final payment of £17,971 – giving you an offer that's at 1.9% APR.
GWM is also introducing new colours to the Ora 03 model range. This includes metallic Moonlight White paint option with a contrasting Starry Black roof. The Ora 03, along with these new colour choices, will be showcased at ‘Everything Electric', GWM Ora's first UK event of 2024, from 28th to 30th March.
The brand believes in itself and has strong backing, which is why it is expanding its retail infrastructure to have 30 points of representation across the UK and partnering with 16 trusted retailers.
Looking ahead to 2024, GWM Ora will carry on trying to make a space for itself in the crowded EV market, with the introduction of additional Ora 03 variants – including a sport-inspired GT model and the eagerly awaited premium saloon, Ora 07. It also plans to add one new retail point of presence each month, going forward.
UK Car Sales (by unit) for 2022
The post ORA rebrands Funky Cat to try and help boost sales first appeared on WhichEV.Net.




